DebateFlow
A benchmark for evaluating how well LLMs judge multi-turn debates.
I've judged over a hundred competitive debates in Karl Popper format. DebateFlow generates synthetic debates with an injected weakness on one side and asks LLMs to call the winner — measuring where multi-turn judgment fails, and how badly.
I’ve judged over a hundred competitive debates in Karl Popper format, and I’ve been curious for a while whether LLMs could do the same job. Not scoring a single argument — there are benchmarks for that — but following a full four-turn exchange and figuring out who actually won. That’s the hard part: tracking which arguments got answered, which got dropped, whether someone shifted strategy mid-debate or just repeated themselves louder.
Turns out the existing research (Wachsmuth et al. 2024, Sanayei et al. 2025) confirms the intuition — LLMs struggle with exactly the things that make multi-turn judging hard. Position bias, length bias, trouble with non-linear reasoning. So I built DebateFlow to measure where they fail, and how badly.
The setup
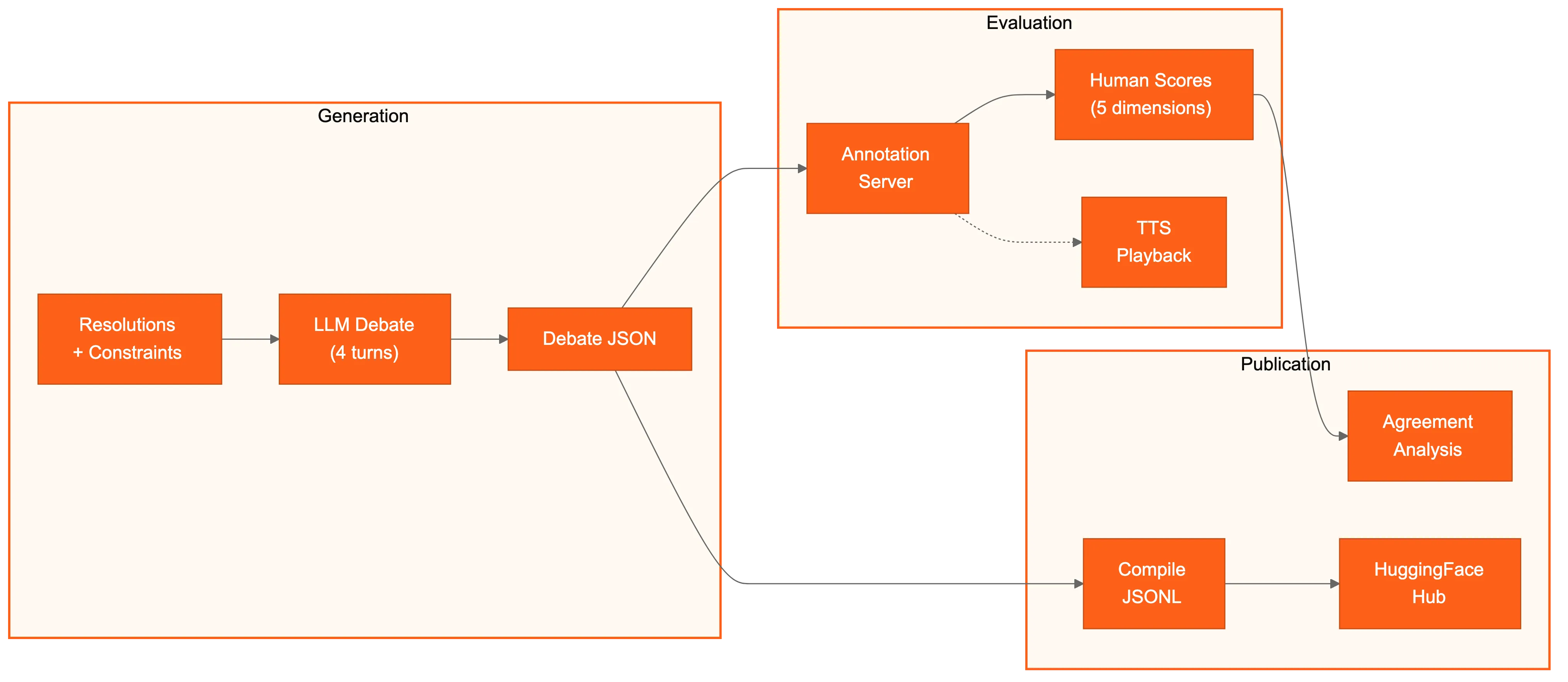
DebateFlow generates synthetic debates: two LLMs argue against each other in Karl Popper format (Affirmative opening → Negative response → Affirmative rebuttal → Negative closing) across policy, values, and empirical topics. The trick is that one side gets an injected weakness — sloppy evidence, a dropped argument, a logical gap — so there’s a known ground truth to evaluate against.
What gets scored
I designed a 5-dimension rubric for the task. Three dimensions adapt existing argumentation theory to multi-turn context: clash engagement (did you address the other side?), burden fulfillment (did you prove what you needed to?), and rebuttal quality (how deep were your refutations?). Two are new, because nothing in the single-argument literature captures them: argument extension (did your case develop across turns, or did you just say the same thing again?) and strategic adaptation (did you actually respond to what your opponent did?). These are exactly the things I spend the most time explaining to new judges.
The annotation pipeline
Human annotators score debates through a browser-based tool with optional text-to-speech playback (surprisingly helpful for catching things you’d miss reading). There’s also a Telegram bot for distributed annotation. Everything gets compiled and published to HuggingFace Hub with full provenance — which models debated, what weakness was injected, who annotated what.
¶ Curious about how it works? Get in touch ↗