code 
ChatGPT makes side projects easy: a case study
An article about Greybox Wrapped published on Linkedin.
23 Apr, 2023 - 01 Min read

In September 2021, I spent the last 36 hours on a rollercoaster made of snakemake, {Rmarkdown}, {renv}, and conda/Docker. The ending had me think I might become the Joker. But the journey was fun.
@Laura_Kellman spent the last couple of years working on a cutting-edge cancer genomics project, accumulating many gigabytes of files and writing tens of RMarkdown notebooks. I volunteered to do a code review and functional replication on another machine.
Where do you start when you want to do this? Gather everything.
data/ subfolder.To be able to track any changes to the scripts, as well as any alterations to the data generated, we initialized a git repository in RStudio and threw everything in it. And I mean everything, including - perhaps against best practice - data files of up to 1 GB.
(Yes, it would have been better to install git-lfs or git-annex. You certainly cannot do this with really big data, but we decided everything under 1 GB was fair game, despite RStudio’s heartfelt protests. The idea is that this repository is perhaps not the version history we’ll share, but rather a safety net beneath our efforts.)
Note that if you do this, you cannot upload the repository to GitHub straight away. You’ll need to either purge the large files from the version history; or discard this version history altogether (i.e. remove/rename the .git folder), re-initialize with an updated .gitignore, and git add only the things you want to share.
{here}Hard-coded paths are common in academic code. Needless to say, they have to go! The main solution in this space is {here}, which basically looks through parent folders recursively until it finds one with an .Rproj file or a .git folder, which indicates that the project root has been located, and then make all paths relative to that.
In other words: read_csv(here("data/input.tsv")) is unambiguous, whereas read_csv("~/Documents/Projects/MPRA/Attempt3/data/input.tsv") only works on one machine, and only if you never move the project folders.
{renv} and R{renv}, the preeminent dependency management for R, was a clear choice. We installed it from Github, initialized it (renv::init()), installed RMarkdown to allow it to parse packages from RMarkdown sources with renv::hydrate(), let it install everything, and then saved it to a lockfile so that we could reproduce it at will (renv::snapshot()).
(I actually made a mistake here — I hadn’t checked what R version Laura had been using, nor have I updated the R that ran on my machine, so we ended up on R 4.0.2 instead of Laura’s R 3.6.1 or the latest R 4.1.1. To my surprise, this presented less of a problem than I thought it would. Still, don’t repeat my mistake! Think of your R version first.)
Why not conda? The main alternative to {renv} was conda with r-forge and bioconda channels. Historically, those have been more painful and often incomplete, plus it doesn’t play nice with RStudio. In hindsight, though, conda was worth attempting, if only to see whether it could make the work with Snakemake easier.
For the past several years, I’ve used Makefiles to document my data processing workflows. I’ve read about Snakemake, but I didn’t have time to try it out. Then the time came to help @Laura_Kellman optimize her PhD data processing workflow, so of course I thought now is the time to experiment. (Sorry, Laura.)
To be fair, Snakemake had quite a few features to offer over GNU Make! But I’ve only ever read the docs and haven’t actively deployed it. Rookie mistake.
{renv} + {RMarkdown} really don’t play nice. script: "X.Rmd" will fail without an explicit error; with the benefit of hindsight, I guess {RMarkdown}/{knitr} was only installed in the {renv} library and so the very first command that Snakemake was trying to execute was failing. It sure feels like it could tell me that, though, instead of failing with a meaningless StopIteration error and nothing at all in the log file!{renv} + bare R don’t play nice, but just in a regular way. By default, Snakemake will call any R script with Rscript --vanilla {script}, which intentionally skips loading .Rprofile, which is {renv}’s entire mechanism of action. To counteract that, add source(".Rprofile") to the top of the scripts.{renv} + {RMarkdown} in a separate conda environment? Yeah, couldn’t get that working at all.So, what worked?
Snakefile clarified where to start and which scripts depend on which. It made it easy to write a bare R script that would run all the notebooks in order, which is basically a low-tech Makefile.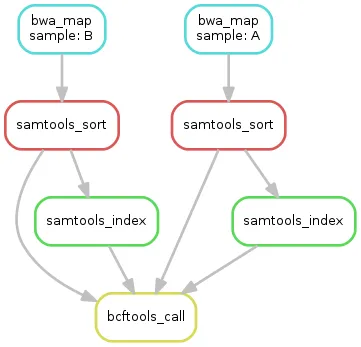
{renv})Having a cross-platform replication of the pipeline was already good news, but to make the project run anywhere, we had wanted a Docker container runtime for it.
(If you’ve never heard of Docker, imagine a blank-slate computer that you set up just to run your code. Instead of manually tuning it, you write up every step of the setup in an automated instruction file called the Dockerfile. That way, anyone can set up that same blank-slate computer and anyone can run your code!
…if this isn’t clear, see Boettiger (2014) and Nuest et al. (2020).)
Here were the issues I encountered along the way:
{renv} play games, at least if your plan is to bind-mount the project in at runtime. By default, renv::restore() puts files in your project/renv/library/R-{version}/{system/architecture} - which of course won’t work if you’re mounting project/ over it. One way to get around this is to call renv::isolate(), which appears place your local library in /usr/local/lib/R/site-library - but then you can’t let .Rprofile run (because it will redirect your .libPaths() to the local renv/ folder), so you have to run your mounted scripts with Rscript --vanilla {script} and you can’t explicitly invoke source(".Rprofile") or you’ll break it. (You’ll note that this is, ironically, the exact opposite of what you need to do to work around Snakemake + {renv} interoperability.)There wasn’t time to do everything. The specific omissions are the following three things in particular:
assertr or input/output tests with great_expectations.This was unreasonably fun, so much so that I’d consider a job doing nothing but helping bioinformaticians with their pipelines (and briefly looked for it - let me know if you know of one). It was also much, much slower than anticipated, and converted me into a Snakemake skeptic in a way I didn’t anticipate. Looking forward to the next time!
An article about Greybox Wrapped published on Linkedin.
23 Apr, 2023 - 01 Min read

I allowed myself to be nerd-sniped into a battle of statistics. The result is a blog post about prejudice in the EU, with a lot of pretty graphs.
02 Sep, 2017 - 01 Min read
Have a question, an idea, or just want to say hello?